Anthropic 最近发布了一个构建 skills 的完整指南,信息量很大,我们一起来拆解下核心内容。
你有没有这种感觉:每次让 AI 做同一类事情,都要重新把流程、偏好、规范解释一遍?Skill 就是来解决这个问题的,写一次,反复用。
最近养虾 OpenClaw 真的非常火,而 OpenClaw 的一大核心能力就是可以使用 skill 来扩展各种能力。如果你有一些流程化的重复性的工作,完全可以写成一份 skill,让小龙虾或者其他 Agent 来承接工作。
Skill 基础
关于 Skill 是什么,我在 Agent Skills:把你的 Claude Code升级为定制的工作平台 里已经写过了,这里快速过一遍几个重要的点。
文件结构
一个 Skill 就是一个文件夹,结构如下:
1 | your-skill-name/ |
只有 SKILL.md 是必须的,其余都是按需加载的资源。有几个命名规则要注意:
- 文件名必须是
SKILL.md,大小写敏感,不接受skill.md或SKILL.MD - 文件夹名用 kebab-case:
notion-project-setup✅,不能有空格或大写 ❌ - 不要放
README.md,文档统一放进SKILL.md或references/
核心设计:渐进式披露
Skill 的内容不是一次性全部塞给模型的,而是三层按需加载:
- 第一层(YAML frontmatter) :Claude 启动时就加载,帮助模型判断”我该不该用这个 skill”
- 第二层(SKILL.md 正文) :当模型决定用这个 skill 时才读取,包含完整的指令
- 第三层(引用文件) :skill 目录下的其他文件,只有正文里引用到时才被加载
这个设计的妙处在于,不管你启用了多少 skill,token 消耗始终可控。
description:最关键的一个字段
第一层里的 description 字段,直接决定了 Claude 会不会用你的 skill。它需要同时包含 做什么 和 什么时候用 两个信息。
好的 description:
1 | description: 管理项目迭代工作流,包括迭代规划、任务创建和进度追踪。 |
差的 description:
1 | description: 帮助处理项目。 |
差距一目了然。一个调试技巧:直接问 Claude “你什么时候会用 xxx 这个 skill?”,它会把 description 复述出来,你一看就知道触发逻辑清不清晰。
三类典型用途
在动手写之前,先想清楚你的 skill 属于哪种类型,不同类型的写法侧重点不一样。
类型一:文档和资产创建
用来生成高质量且格式一致的输出,比如文档、PPT、前端设计稿、代码片段等。不依赖外部工具,完全用 Claude 内置能力。
核心技巧:嵌入风格指南和品牌标准、提供模板结构、在输出前加质量检查清单。
类型二:工作流自动化
用来编排多步骤流程,可以跨多个 MCP 服务协调操作。官方的 skill-creator 就是这个类型,引导用户一步步完成 skill 的构建和验证。
核心技巧:分步骤并在每步设置验证门槛、内置模板结构、配置迭代优化循环。
类型三:MCP 增强
在 MCP 服务器提供工具访问的基础上,叠加工作流指导和领域知识。比如 Sentry 的 sentry-code-review skill,能自动通过 Sentry MCP 分析 GitHub PR 里的 bug 并给出修复建议。
核心技巧:按顺序协调多个 MCP 调用、嵌入领域专业知识、帮用户省去手动指定上下文的步骤、完善错误处理。
Skill 和 MCP 的关系
很多人会问:有了 MCP 还需要 Skill 吗?其实它们不是替代关系,而是互相配合的。
原文用了一个厨房类比,我觉得很贴切: MCP 是专业厨房 ,提供了各种工具、食材和设备; Skill 是菜谱 ,告诉你怎么用这些东西做出一道菜。
5 个实战模式
这是官方指南里最有价值的部分。不同场景适合不同的 skill 结构,下面逐个拆解。
模式一:顺序工作流编排
适合场景 :用户需要按固定顺序完成多步操作,比如客户入驻、项目初始化。
核心是把步骤顺序和步骤之间的数据依赖写清楚。
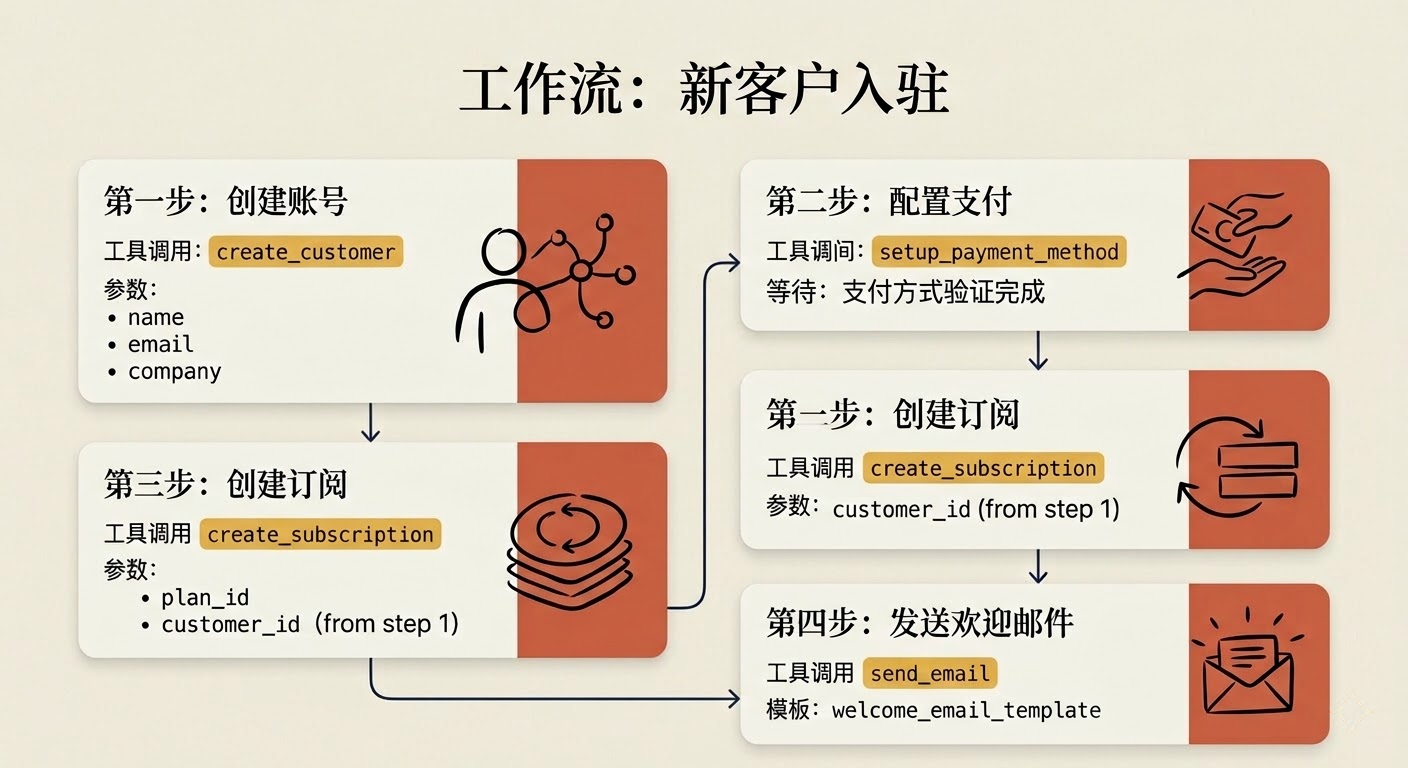
1 | ## 工作流:新客户入驻 |
关键技巧:
- 明确标出步骤顺序和步骤之间的数据依赖(比如第三步用到第一步创建的 customer_id)
- 每步都要有验证
- 失败时提供回滚说明
模式二:多 MCP 协调
适合场景 :一个工作流横跨多个服务,比如设计稿交付开发这种流程。
这个模式的难点在于数据在不同服务之间传递,skill 里要明确定义每个阶段的输入输出。
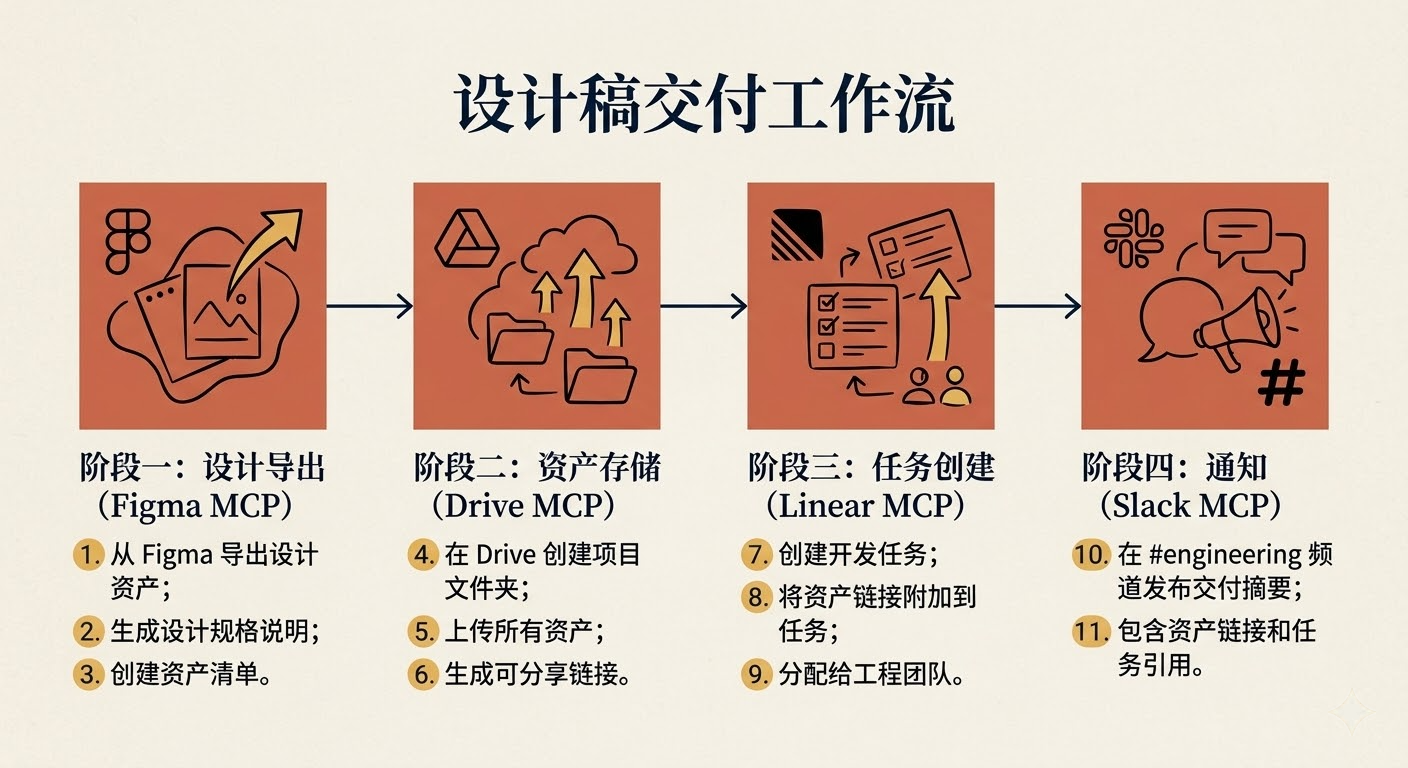
1 | ## 设计稿交付工作流 |
关键技巧:
- 用”阶段”而不是”步骤”来划分,每个阶段对应一个服务
- 明确哪些数据需要从上一阶段传过来
- 进入下一阶段前要验证上一阶段是否成功
这个模式对于 MCP 构建者来说特别值得注意,当你的用户接入多个 MCP 时,一个 skill 可以把散落的工具串起来,比分别手动调用每个工具体验好太多。
模式三:迭代精炼
适合场景 :输出质量需要通过多轮迭代才能达到标准,比如报告生成、代码审查。
这个模式的核心是一个循环:先检查质量,找到问题就修,修完再查,直到达标才停下来。
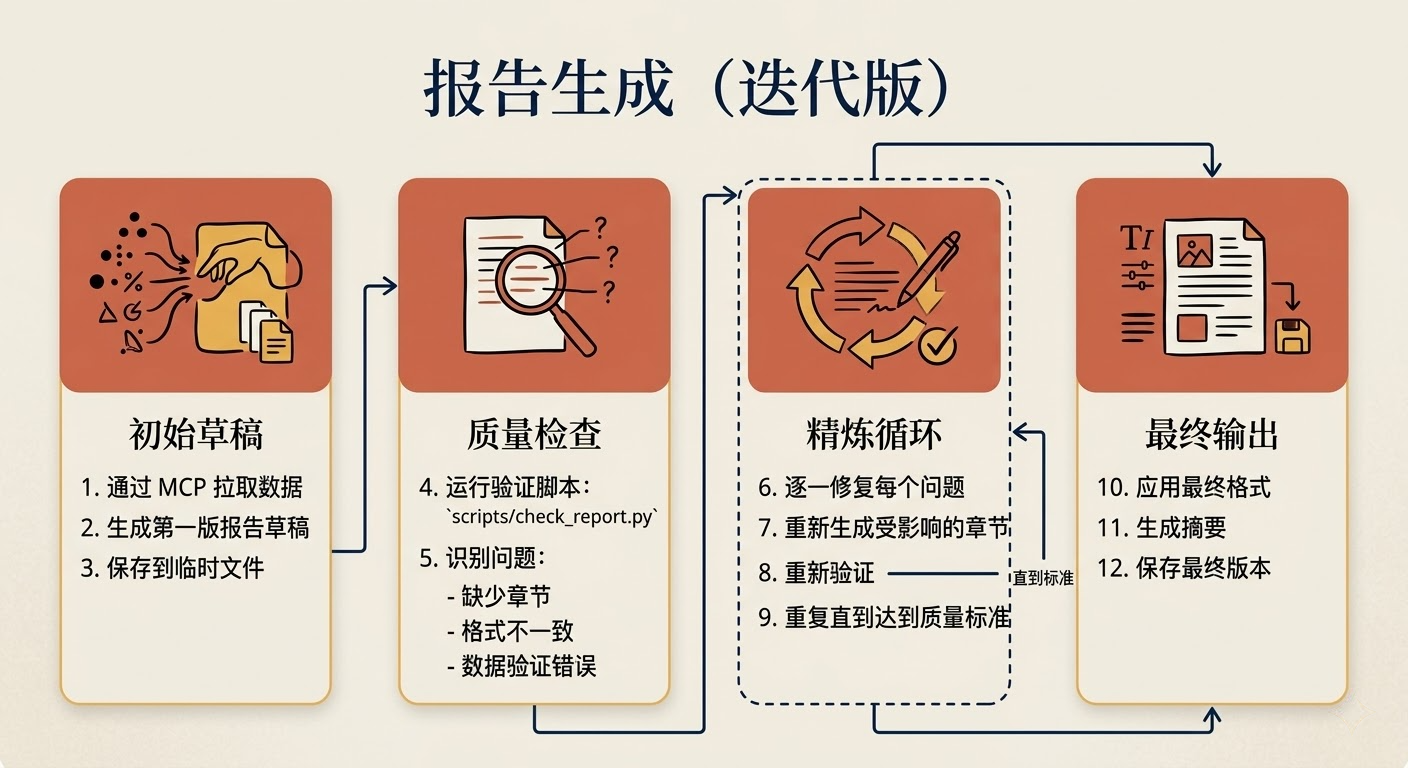
1 | ## 报告生成(迭代版) |
关键技巧:
- 明确”达到标准”是什么,不然会无限循环
- 验证脚本比文字描述的验证更可靠,代码是确定性的,语言是模糊的
- 迭代次数要有上限
模式四:上下文感知工具选择
适合场景 :同一个目标,根据不同情况选用不同工具,比如文件存储该用哪个服务。
在 skill 里埋入决策逻辑,让 Claude 根据具体情况自动选择合适的工具。
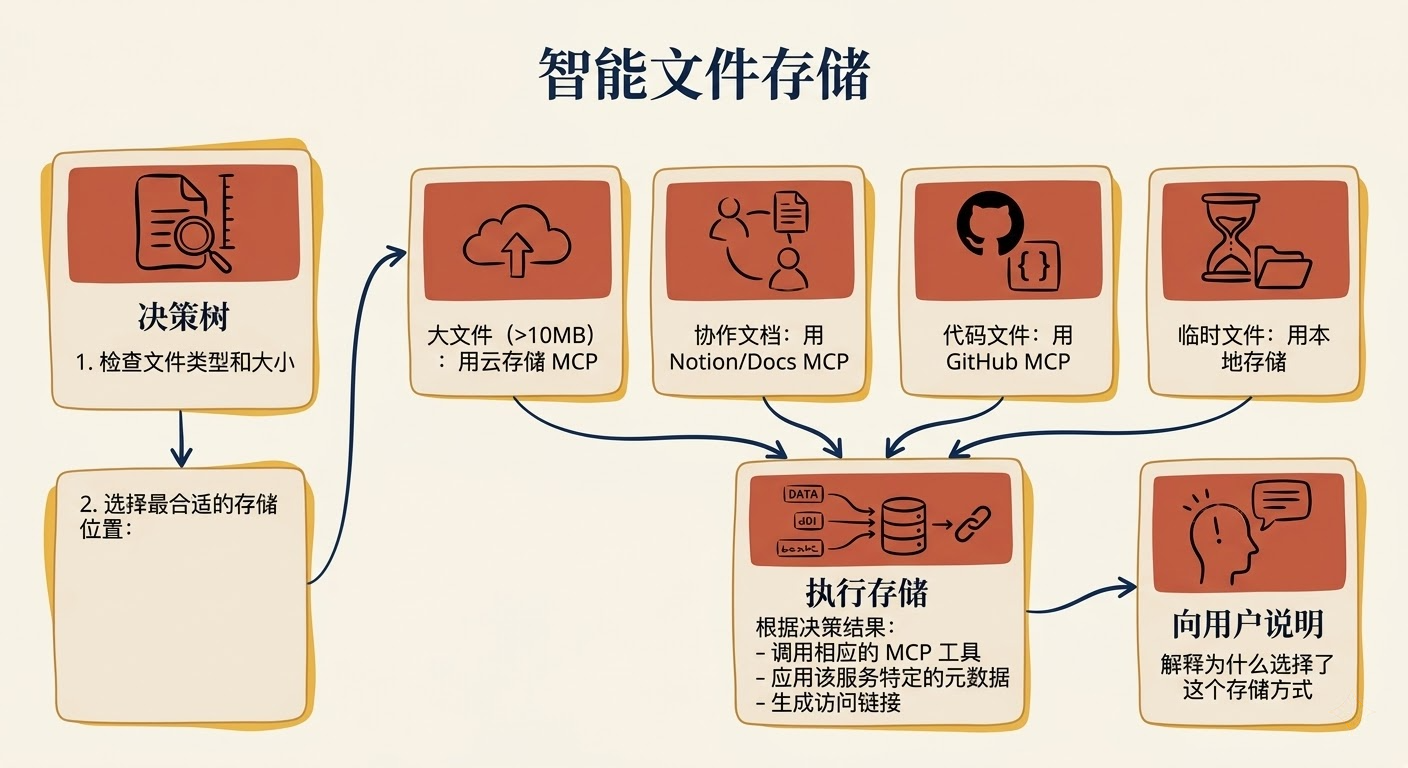
1 | ## 智能文件存储 |
关键技巧:
- 决策标准要清晰,不能有歧义
- 每个选项都要有备选方案
- 向用户说明选择原因,增加透明度
模式五:领域专业智能
适合场景 :skill 不只是调用工具,更是把特定领域的知识和规则编码进去,比如合规检查、财务处理,或者代码审查时自动检查安全漏洞、发布前检查是否符合团队的代码规范等。
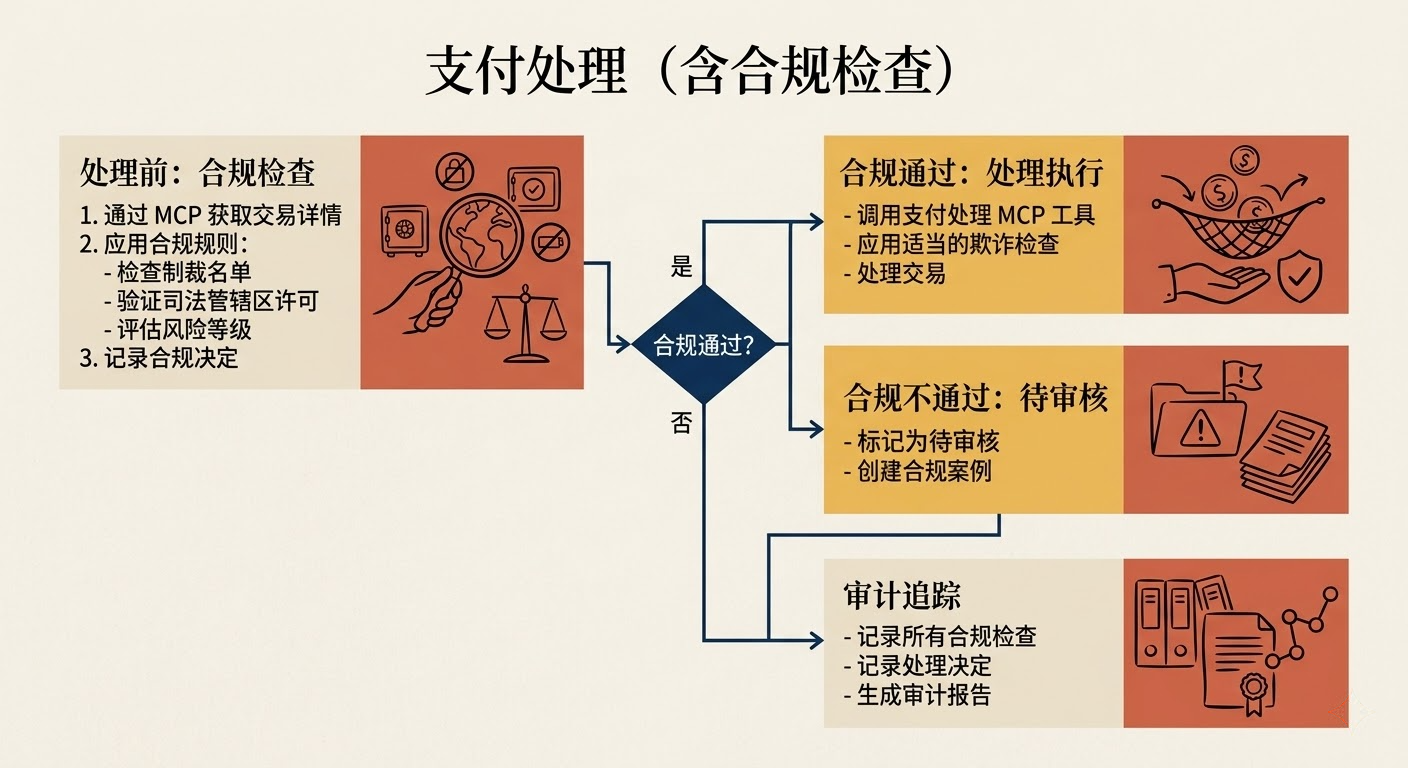
1 | ## 支付处理(含合规检查) |
关键技巧:
- 把领域专业知识直接写进逻辑,而不是期待用户自己带入
- 执行前先做合规/验证,而不是事后处理
- 完整的文档和审计追踪
Skill 写完不是终点,触发行为对不对、输出结果好不好,都需要验证。官方推荐关注三个方面:
- 触发测试 :准备一批测试查询,验证 skill 在该触发时触发、不该触发时别乱触发
- 功能测试 :输出格式对不对、API 调用成不成功、错误处理符不符合预期
- 性能对比 :同样的任务,有 skill 和没 skill 对比一下对话轮次和 token 消耗
实际用下来,最常遇到的两个问题:
- 触发不足 :skill 该触发但没触发。修复方法是在 description 里加入更多用户实际会说的关键词
- 触发过度 :不相关的场景下也加载了。修复方法是加负向触发条件,比如 “不适用于简单数据探索”
如何分发你的 Skill
推荐的方式是放到 GitHub 公开仓库,然后在你的 MCP 文档里链接过来,并说明为什么两者结合使用更好。
一个好的 skill README 应该关注结果,而不是技术细节:
好的描述:
“ ProjectHub skill 让团队可以在几秒内搭建完整的项目工作区,包括页面、数据库和模板,而不是花 30 分钟手动配置。”
差的描述:
“ProjectHub skill 是一个包含 YAML frontmatter 和 Markdown 指令的文件夹,会调用我们的 MCP 服务工具。”
Skill 上传失败
Could not find SKILL.md:文件名大小写不对,必须是SKILL.md,不能是skill.md或SKILL.MDInvalid frontmatter:YAML 格式有问题,检查是否有---分隔符,引号是否闭合Invalid skill name:name 字段必须是 kebab-case,不能有空格和大写
Skill 不触发
description 写得太模糊,改写建议:把用户实际会说的话写进去,比如”当用户说’帮我规划冲刺’或’创建任务’时使用”。
MCP 连接正常,但 skill 里的 MCP 调用失败
先单独测试 MCP:”用 [服务] MCP 获取我的项目列表”,如果这个都失败说明问题在 MCP 不在 skill。
然后检查 skill 里引用的工具名称是否和 MCP 文档里的完全一致,工具名是大小写敏感的。
Skill 加载了,但 Claude 没有按指令执行
常见原因:指令太长导致关键步骤被淹没、措辞太模糊(比如”验证数据”不如明确列出验证项)、SKILL.md 超过 5000 字撑爆了上下文。解决思路是用要点列表突出关键步骤,把详细文档移到 references/ 目录按需加载。
回顾一下,构建一个好的 Skill 关键就三件事:把 description 写清楚让触发精准、选择合适的模式来组织你的指令、写完之后做测试并持续迭代。
Skill 和 MCP 是搭档关系,不是替代关系。MCP 负责连接外部服务,Skill 负责把使用这些服务的最佳实践固化下来。两者结合才能让 Agent 真正可靠地完成复杂任务。
建议从你日常工作中一个简单的重复性场景开始,用 skill-creator 跑通一个最小版本,再逐步扩展。
- Agent Skills:把你的 Claude Code 升级为定制的工作平台
- The Complete Guide to Building Skills for Claude
- Skill authoring best practices
- Equipping agents for the real world with Agent Skills